Highlights
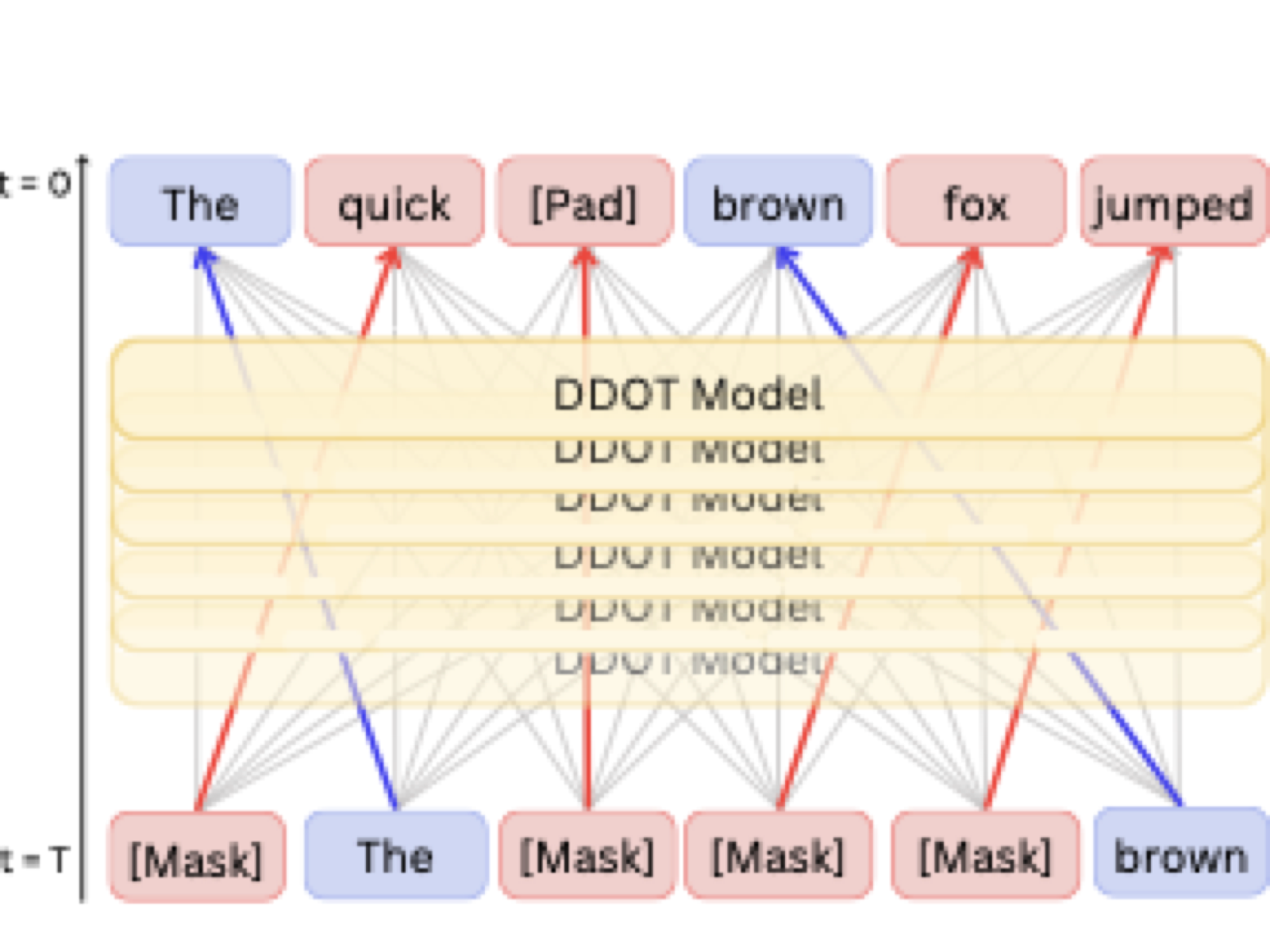
Joint token & position diffusion
DDOT simultaneously denoises discrete token values and continuous positions so infilled spans can slide, stretch, or shrink while preserving parallel generation.
Sample-level optimal transport
Order-preserving optimal transport couplings align noisy and ground-truth positions within prompt and response sets, collapsing the permutation space and stabilizing training.
Flexible infilling accuracy
The uniform variant DDOT-U hits 58.4 BLEU-4 with 100% success on One-Billion-Word block infilling and mirrors that reliability on Yelp block spans, results now published in the EMNLP 2025 proceedings.
Abstract
Discrete diffusion models are a new class of text generators that offer advantages such as bidirectional context use, parallelizable generation, and flexible prompting compared to autoregressive models. However, a critical limitation of discrete diffusion models is their inability to perform flexible-length or flexible-position text infilling without access to ground-truth positional data.
We introduce DDOT (Discrete Diffusion with Optimal Transport Position Coupling), the first discrete diffusion model to overcome this challenge. DDOT jointly denoises token values and token positions, employing a novel sample-level Optimal Transport (OT) coupling. This coupling preserves relative token ordering while dynamically adjusting the positions and length of infilled segments, a capability previously missing in text diffusion.
Our method is orthogonal to existing discrete text diffusion methods and is compatible with various pretrained text denoisers. Extensive experiments on text infilling benchmarks such as One-Billion-Word and Yelp demonstrate that DDOT outperforms naive diffusion baselines. Furthermore, DDOT achieves performance on par with state-of-the-art non-autoregressive models and enables significant improvements in training efficiency and flexibility.
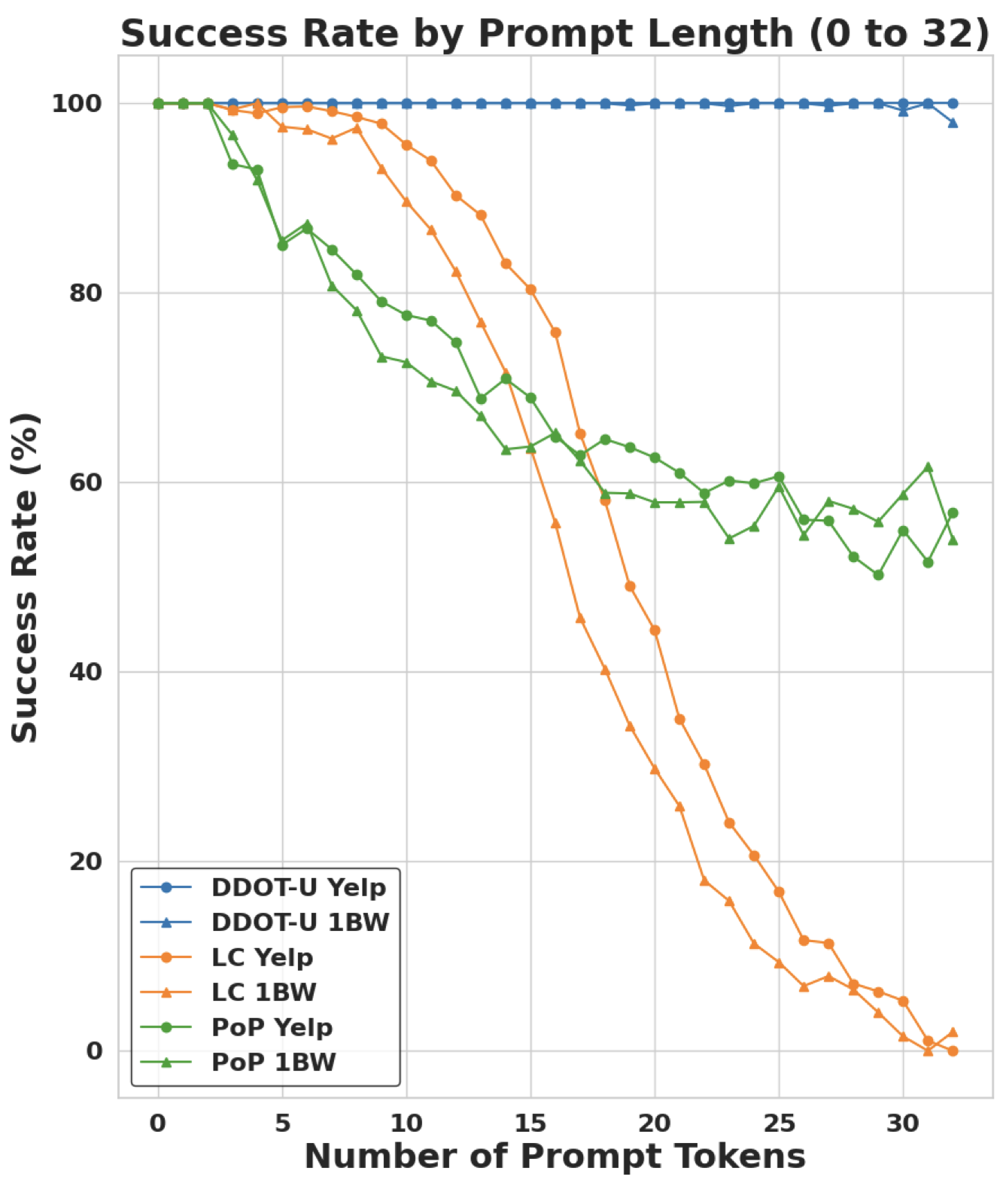
DDOT maintains near-perfect success as prompts grow, while LC and PoP quickly generate invalid outputs.
Longer reverse schedules improve BLEU and METEOR, showing DDOT benefits from additional denoising steps.
DDOT respects prompt keywords while generating coherent sentences on One-Billion-Word and Yelp benchmarks.
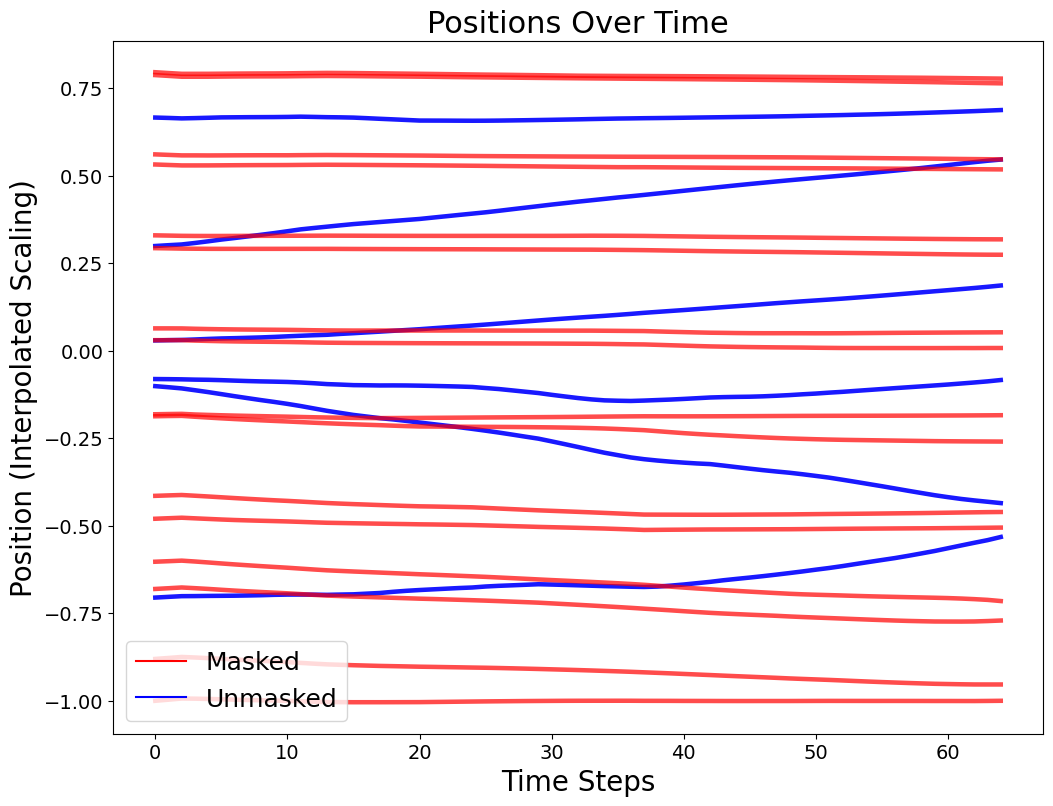
Optimal transport produces straight, non-crossing paths that keep prompt order intact during denoising.
Method Overview
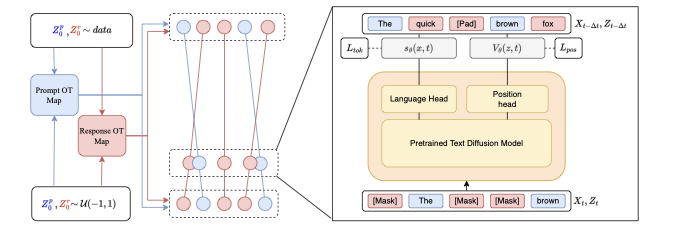
- Joint denoising: A Diffusion Transformer predicts token scores and position velocities in one forward pass, keeping generation parallel while learning to move masked spans.
- Optimal transport guidance: Balanced prompt matching and injective response matching form order-preserving trajectories that clamp prompt order yet allow responses to weave between them.
- DDOT-R vs. DDOT-U: Random terminal sampling provides diverse placements, while uniform grids (DDOT-U) curb pad clustering and consistently deliver the strongest metrics.
Results at a Glance
One-Billion-Word (Block)
DDOT-U: BLEU-4 58.4 · NIST-4 8.79 · METEOR 42.1 · Success 100%
+16.4 success points over PoP while improving BLEU-4 by 8.4.
Yelp (Block)
DDOT-U: BLEU-4 59.5 · NIST-4 8.86 · METEOR 42.9 · Success 100%
Matches the best baselines while keeping every prompt token in place.
CodeParrot (Random)
DDOT-U: BLEU-4 40.4 · CodeBLEU 45.4 · Success 11.2%
Improves CodeBLEU by 25.9 points over PoP for Python infilling.
BibTeX
@inproceedings{zhang-etal-2025-flexible,
title={Flexible-length Text Infilling for Discrete Diffusion Models},
author={Zhang, Andrew and Sivakumar, Anushka and Tang, Chia-Wei and Thomas, Chris},
editor={Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet},
booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing},
month={nov},
address={Suzhou, China},
publisher={Association for Computational Linguistics},
year={2025},
url={https://aclanthology.org/2025.emnlp-main.1597/},
doi={10.18653/v1/2025.emnlp-main.1597},
pages={31344--31359},
isbn={979-8-89176-332-6}
}