Below is list of all the paper reviews I wrote for my graduate multimodal class. The reviews got better as the semester progressed! (Later in the list). In particular, I believe my discussion questions for the guest lecture were interesting.
Summary
This paper introduces Neural Baby Talk, a novel method for generating natural sounding, grounded image captions. Neural Baby Talk uses a two-stage approach to generate either a text token or a visual slot token, which corresponds to a region in the image given by a region proposal network. The paper also sets the state-of-the-art performance on COCO and Flickr30k.
Relation to prior work
Previous image-captioning methods either generate natural-sounding and plausible captions that are incorrect or unnatural-sounding but factually correct captions. On the other hand, Neural Baby Talk attempts to combine the best of both worlds by allowing for arbitrary captions through the generation of text tokens (instead of using fixed caption types) as well as grounded visual tokens. There are many prior works on image-captioning. However, they either tackle a slightly different task such as dense captioning or do not use the hybrid approach proposed by the paper.
Strengths
The paper achieves state-of-the-art performance on COCO and Flickr30k. Unlike previous methods, Baby Neural Talk can generate natural-sounding captions while using grounded tokens, preventing the likelihood of hallucinations. Furthermore, these grounded tokens can use a variety of standard object detectors. As illustrated in Figure 2, the using different detectors creates a diverse set of captions with varying levels of detail. The entire method is also end-to-end differentiable, requiring a very simple training setup.
Weaknesses
Unfortunately, Neural Baby Talk can only generate tokens from the classes that the object detector was trained on. This requires the paper to train the detector on Flickr30k Entities, limiting the generalizability of the model. While this training paradigm is good for achieving SOTA on datasets such as Flickr and COCO, where the classes are known, it would not generalize open-domain image captioning tasks.
Furthermore, the paper uses a pointer network to learn a correspondence between regions in the image and the visual slot tokens. Pointer networks ensure that each element of the input can be “pointed” to once. While it is a reasonable assumption to assume that image captions generally refer to each noun only once, this limits the viability of generating a caption that refers to a noun more than once. For example, the caption “There is a fox jumping over a dog. The dog is brown,” would require the model to refer to the region corresponding to the token “dog” more than once. Such a caption would therefore require the region proposal network to propose two overlapping regions for the dog, one of which would have a lower alignment with the dog token than the top region.
Finally, the plurality prediction stage of the network further limits the generalizability of Baby Neural Talk. First, one must ensure that the chosen word embeddings are all singular, a very manual task. Such a requirement would also interfere with modern tokenization schemes such as byte-pair encoding, where tokens are automatically chosen based on how often they appear in a training corpus. The choice of including a plurality prediction stage makes sense given the available technology at the time. However, it may also artificially inflate the BLEU, METEOR, CIDr, and SPICE scores of the model. These metrics often rely on n-gram exact match on words. Even though the singular and plural versions of the same noun have very similar semantics, these metrics would nevertheless penalize this mistake. Therefore, the plurality prediction stage could bypass the flaw in these metrics, leading to a higher score without better semantic understanding.
Future Work
Since this is an old paper (in terms of the machine learning timescale), there have been many future works derived from the paper. Many modern image-captioning and visual question answering techniques address the weaknesses of Baby Neural Talk. For example, the advent of large language models allows for the generation of open-vocabulary captions. Models such as Flamingo and LLaVA decrease the inductive bias of Neural Baby Talk and simply combine an LLM with a visual encoder. This allows for a more diverse generation of images captions
Summary
The paper “Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering” proposes the Dense Co-attention Network (DCN) for visual question answering. DCN consists of dense co-attention layers. Each layer takes in text and vision features and passes them through a custom attention mechanism that is symmetric between the text and vision streams. Next, These attended features are concatenated with the inputs and fed through a feed forward layer.
The actual attention mechanism of DCN is very similar to the attention mechanism in transformers. However, the softmax is applied in both dimensions of the affinity matrix to produce attention maps for both the vision and text streams rather than softmax in a single direction for a single-stream transformer. There is also no distinction between queries and keys in the DCN layer. Rather, the paper uses a simple dot product between the vision features, text features, and a learned weight matrix to obtain the affinity matrix.
Relation to prior work
There are numerous prior works on using attention for VQA. For example, previous papers suggest varying attention mechanisms such as stacked attention and using co-attention to allow question tokens to attend to certain image regions. The paper argues that the DCN attention mechanism is unique because it models the interactions between every question word and image region, whereas previous methods only considered attention from question words on the whole image or attention from the whole question on image regions.
Strengths
DCN achieves impressive state-of-the-art performance on VQA and VQA 2.0 in all question categories. It is also smaller in parameter-count than most of the baselines.
The paper provides a comprehensive ablation study on the attention direction, memory size, number of parallel attention maps, etc.
The model also does not require external data to achieve these results
Weaknesses
The main weakness of this paper is its similarity to the Transformer architecture. The paper proposes the DCN network to model the interaction between every image region and every text token, something that supposedly sets it apart from prior works. However, concatenating the vision and text features and feeding them through a standard transformer would also model this interaction between every text and vision feature. In fact, this simple transformer would model more attention interactions within the set of text tokens and the set of vision tokens, something DCN does not do.
The use of a residual attention layer followed by a feedforward layer is very similar to the transformer block. Furthermore, the square root scaling on the softmax is also very similar to the attention mechanism in transformers. A comparison to a transformer baseline would be interesting to see. The model was also trained on a train set of 248,349 questions for 16 and 443,757 questions for 21 epochs. This is a significant amount of training data.
Finally, the model achieves SOTA on VQA. However, the improvements are marginal. It is possible that the dataset is saturated, and human performance would also be a good metric to include.
Future Work
There are numerous avenues of future work from DCN. First, DCN could be applied to domains other than text/video. Any pair of modalities such as text/video text/audio could be considered. It would also be interesting to extend DCN to more than a pair of modalities. For instance, text/image/video/audio or text/image/depth could be used.
Summary
The paper proposes a new Vision-Language Pretraining (VLP) method named OSCAR, which uses object tags and corresponding image regions as keypoints to speed up training. More specifically, OSCAR takes in a triple of word embeddings for the entire image, word embeddings corresponding to objects in the image, and a set of regions in the image. OSCAR has two simple losses. The first loss is a standard language-masking loss used by BERT to minimize the negative log-likelihood of the corresponding correct token of a masked token. For the second loss, OSCAR replaces the object tags with a random sequence 50% of the time. Then, a binary classifier on top of the CLS token predicts whether or not the object tags were replaced. The object tag objective uses a standard contrastive loss. The final loss function is the masked-language modeling plus contrastive loss.
Relation to prior work
There are numerous prior works involving VLP and object tags. Previous image understanding methods align image regions with tags. However, the core novelty of OSCAR is that it associates tags with both object regions and the word embeddings.
Strengths
- OSCAR achieves state-of-the-art performance on numerous benchmarks across a wide variety of downstream tasks. This suggests that the features learned by OSCAR are more accurate and more interpretable than previous methods
- The paper provides extensive experiments to study the performance of OSCAR and ablation studies on the efficacy of object tags, the attention interaction between the input triplets, and the impact of different object tags.
- OSCAR uses less pretraining data than previous VLP methods. For example,
Weaknesses
- OSCAR uses Self-critical sequence training (SCST) to directly optimize on metrics such as CIDEr. Therefore the comparison in table 2(e) may not be a fair comparison.
- Although OSCAR uses less pretraining data than other VLP methods, it is initialized from BERT, which has already been pretrained on large-scale web text data. This could also lead to an unfair comparison to other methods. Furthermore, it adds additional constraints to the model. For example, OSCAR must have the same size as public BERT models. It would be interesting to see an ablation study on the impact of pretraining from scratch.
- The performance improvement of OSCAR over previous methods in table 2 are marginal on certain tasks. Specifically, the gap between OSCAR and UNITER is typically within a percent on VQA and NLVR2. There is a larger gap on text and image retrieval.
- There are prior works on aligning image regions with object tags. The core difference is that these tags are not also associated with both the object regions and overall text embeddings.
Future Work
Since the paper argues that the relationship between the object tags and the whole text sequence is important, it would also be interesting to study the effect of adding whole-image features as an input to OSCAR.
Summary
The paper proposes Multimodal Optimal Transport-based Co-Attention Transformer (MOTCat), a method to attend between different modalities. Optimal transport (OT) based attention has various advantages over conventional attention methods. First, it can be applied to larger inputs with the help of micro-batching, something that is crucial for the giga-pixel level whole slide images that the paper experiments on. Second, OT-based attention can model global interactions within tumor microenvironments. MOTCat takes in a bag of pathology images and a bag of genomic information. Both modalities go through their respective encoders. Next, MOTCat applies optimal transport to find a mapping between the modalities in each coattention layer. More specifically, it aims to minimize the ground distance metric between each modality. At the end of the model, MOTCat predicts the survival time of each case. MOTCat achieves state-of-the-art performance on 4 out of 5 benchmarks.
Relation to prior work
There are numerous previous works on multimodal architectures in healthcare and more specifically survival prediction. The most similar work to MOTCat is MCAT, which uses co attention to map information between the WSI and genomic features.
Strengths
- MOTCat achieves state-of-the-art performance on 4 out of 5 benchmarks. Furthermore, MOTCat it outperforms the most similar baseline MCAT, on all benchmarks
- MOTCat models global interactions between the two modalities, something that is computationally intractable with conventional attention methods
- The paper provides comprehensive ablation studies on the effect of using different microbatch sizes and whether or not to use optimal transport.
Weaknesses
- The performance increase from using optimal transport seems marginal in the Table 2 ablation study. The majority of the performance comes from using MOTCat without optimal transport, which is usually in the range of 1%. On the other hand, the performance gain from MOTCat without optimal transport to MOTCat with optimal transport is usually within 0.1%. This suggests that the use of optimal transport may not be the primary factor behind the state-of-the-art results on 4 out of 5 benchmarks.
- The paper gives the training and inference speed of MOTCat in section 4.3 However, it does not compare the speed to baselines. It is a bit weird that raw numbers were listed rather than a comparison, and I do not have a graph for what magnitude of “patches per second” on an RTX 3090 is a good number.
- The technique of using a subset of features during optimal transport also seems hacky. It could lead patches to miss information from other patches during the coattention. Furthermore, the ablation on microbatching is not convincing. The paper does not provide the performance of the model with no microbatching but instead provides two attention methods that are both performed over the microbatch.
Future Work
There are many avenues of future work. One such avenue is to allow the model to intersperse standard attention layers with OT-based attention layers. Another avenue is to use efficient attention techniques such as Linear Attention and Mamba.
Summary
The paper proposes SoftMask, a method to encourage vision-language models to pay more attention to the entire image rather than only discriminative parts of the image. More specifically, SoftMask uses GradCAM to gauge how important parts of the image are. Next, it multiplies the embeddings by 1 minus the normalized values from GradCAM, encouraging the model to pay attention to parts of the image with lower gradients. SoftMask also uses 3 losses: image-text matching, image-text contrastive, and masked language modeling.
Relation to prior work
There are many previous works on vision-language representation. ALBEF is likely the most related work, as the paper builds off the ALBEF architecture. ALBEF uses a vision transformer with contrastive loss to align vision and text.
Strengths
- SoftMask beats most previous methods that were trained on the same amount of data. IN particular, they mostly achieve top performance within this class of models on Flickr30K, MS-COCO, SNLI-VE, NLVR^2, and VQA.
- Despite needing to calculate gradients in GradCAM, SoftMASK requires 1.98 seconds per iteration vs 1.94 seconds compared to the baseline. It also requires 41.4 GB vs 41.5GB.
- The ablation study in Table 4 shows that SoftMask provides a performance increase.
Weaknesses
- The paper does not show experiments on inference-time compute requirements. During training, the gradients for GradCAM are already computed, so they do not add to the compute time. However, this method may be a lot slower during inference because it has to calculate gradients.
- The paper performs data augmentation despite arguing that SoftMask already prevents overfitting. Data augmentation provides similar performance boosts as SoftMask, and combining both provides minimal benefit. They may perform the same task.
- Performance on many benchmarks are saturated or the performance gain from SoftMask is marginal. Many of the results in table 1 are above 95%. Furthermore, performance increases compared to previous methods are typically within 1%
- The justification of randomly sampling a single word instead of using all tokens for GradCAM to boost stochasticity is weak. It further suggests that SoftMASK augments the data, and that attending to less-salient parts of the image is not actually that important.
- SoftMask is not effective for language modeling. MLM loss is worse than ITM loss on MLM performance in Table 6.
- Image and text must be jointly fed through the model
Future Work
One possible avenue of future research is to use a bidirectional soft-masking technique. Currently, the mask is only applied to the image, but it would also be interesting to see the mask applied to the text side.
Summary
The paper proposes FuseMix, a method of data augmentation to supposedly help in boosting the performance of multimodal retrieval. More specifically, FuseMix performs a linear interpolation between two positive pairs of data. The paper also claims that using frozen pretrained unimodal encoders and training light-weight alignment modules on top is a more efficient than training a multimodal retrieval model from scratch (duh)
Relation to prior work
The most related work to FuseMix is Mixup, which performs a linear interpolation between different data points. Many works have built on top of Mixup. Unlike Mixup, FuseMix is applied to the latent space of pairs of data. However, the idea of adding trainable layers on top of a frozen pretrained model has been done many times before.
Strengths
- the paper uses ∼ 600× less compute and ∼ 80× less image-text pairs than CLIP and also outperform CLIP on retrieval tasks
- The proposed method is agnostic to the choice of unimodal encoder. Therefore, people can choose more advanced unimodal encoders as they are released to the public.
- Since the unimodal encoders are frozen and at the beginning of the model, their activations can be precomputed. The method only requires a single V100 GPU
Weaknesses
- The proposed idea of using a pretrained model and adding finetuned layers on top is not new.
- Results are presented with the largest available unimodal encoders. The largest version of DinoV2 is 1.1 billion parameters, so inference time compute requirements are likely a lot higher than baselines. Performance seems to heavily depend on encoder size, as shown in Figure 5(a).
- The ablation study on the linear interpolation method of FuseMix is lacking. Given that FuseMix is the slightly novel contribution of the paper, it would be nice to see results other than R@1 with one combination of latent space from the given encoders. Furthermore, the paper doesn’t mention whether the augmented data adds to the number of training iterations when compared to no data augmentation (it likely does since even adding gaussian noise boosts performance in the ablation).
- The comparison with CLIP in the bottom half of Figure 1 is an unfair comparison. This instance of CLIP was trained from scratch whereas FuseMix used pretrained unimodal encoders that used massive datasets.
Future Work
One possible avenue of future work is to use different types of interpolation. For example, it would be interesting to use methods of interpolation that take into account neighboring image patches such as bilinear interpolation. The current method of linear interpolation only takes into account the current feature. Another avenue of future work is to apply the interpolation at different layers within the network.
Summary
The paper proposes UniPerceiver-v2, a model capable of multiple vision-language tasks. To boost performance, UniPerceiver-v2 uses Task-Balanced Gradient Normalization (TBGN). UniPerceiver-v2 achieves SOTA results among generalist models.
Relation to prior work
There are many previous works on generalist models. Some, such as Flamingo, adopt seq2seq formulations. Another class of generalist models, called uniperceivers, use maximum likelihood to train each task. UniPerceiver-v2 is the first to do detection and segmentation tasks.
Strengths
- UniPerceiver-v2 handles detection and segmentation unlike previous uniperceivers because it encodes localization information.
- UniPerceiver-v2 proposes a novel idea for normalizing gradients with unmixed data sampling.
- UniPerceiver-v2 beats all previous generalist models on performance in Figure 2.
Weaknesses
- The comparison in Figure 2 for retrieval tasks is unfair because UniPerceiver-v2 needs to use a decoder after fusion, especially when compared to ALIGN.
- The paper claims “the task-specific fine-tuning paradigm would result in prohibitive marginal cost.” However, UniPerceiver-v2 uses a massive training corpus to learn all of its target tasks, consisting of ImageNet, COCO, SBU Captions, Visual Genome, and many more datasets. UniPerceiver-v2 already relies on pretrained models, so it can be seen as performing the finetuning stages of multiple tasks simultaneously. Therefore, it may be more performant and efficient to simply finetune foundation models per task. Unfortunately, there is no experiment comparing UniPerciever-v2 with fine tuning on a single task, but table 3 already suggests that adding tasks to the training dataset hurts performance.
- The paper claims that image generation was not evaluated due to computational limitations. However, it is questionable whether this simple encoder-decoder architecture would generate realistic images regardless of compute resources.
- One key novelty that separates UniPerceiver-v2 from other UniPerceivers is that it can handle detection and segmentation. However, it has to add bounding-box and mask features to each region. It would be interesting to see if more features would need to be added for additional tasks. For example, would depth or surface-normal features be necessary for their respective tasks?
- In section 5.2, the paper claims that “combining global and regional representations … achieve[s] the best overall results on all tasks.” However, regional features outperform global + regional features on COCO Retrieval and COCO Caption in Table 2. Furthermore, global features come within 0.1% compared to global + regional on ImageNet-1k classification.
Future Work
One possible line of future work is to eliminate the dependency on separate features for bounding boxes and masking. It would be interesting to find a way to combine both the semantic and spatial features into a single embedding.
Summary
The paper proposes MaPLe, a prompt learning method that works in both the image and text encoders. More specifically, MaPLe inserts learnable tokens in the first J layers of the text encoder. Each of these layers also has a linear projection that maps the learned tokens in the text space to learned tokens in vision space. These learned vision tokens are inserted into the first J layers of the vision encoder.
Relation to prior work
MaPLe builds on the prompt-tuning line of work. Several notable papers such as CoOp proposed learnable tokens to improve the performance of CLIP. Co-CoOp improved CoOp’s performance on novel classes by conditioning prompts on images. Unlike previous methods, MaPLe applies prompt tuning to both the vision and text encoder.
Strengths
- MaPLe proposes the novel idea of putting learnable tokens in vision encoder and a coupling method to allow gradients to flow between the learned prompts in both modalities.
- MaPLe outperforms previous prompt tuning methods while maintaining comparable compute requirements, as illustrated in Table 1. Specifically, it averages 2.72% over Co-CoOp across base and novel classes.
- MaPLe generalizes better than previous methods. In other words, it does better on novel classes, as seen in Table 2.
- MaPLe requires half the number of training epochs to converge compared to Co-CoOp
Weaknesses
- The GFLOPS metric in table 1 is not illustrative of how much compute MaPLe adds versus previous prompt tuning methods because it is dominated by the base CLIP model. MaPLe adds 10x the number of parameters when compared to the previous SOTA (Co-CoOp), as shown in Table 6.
- The number of inserted tokens in the text encoder has to be the same as the number of inserted tokens in the vision encoder. It would have been cool to see a mapping that allows for a different number of tokens in each modality as a hyperparameter.
- MaPLe performs worse than CoOp on base classes (Table 2)
Future Work
There are many possible ways to extend MaPLe. One such possible line is to explore different coupling techniques. MaPLe uses a very simple linear projection from the text to the vision encoder. However, it would be interesting to enforce an invertibility constraint and to alternate between mapping from text to vision and vision to text. A simpler symmetric approach would be to learn latent tokens and provide two linear mappings to each respective modality.
Another possible future work is to explore how to determine which layers to add learnable prompts to. MaPLe currently adds prompts to the first J layers. However, they could space out the learnable prompts every couple of layers.
Summary
The paper proposes LLaVa 1.5, a continuation of the LLaVa series of VLMs with numerous improvements. Specifically, LLaVa 1.5 uses a MLP instead of a linear projection to connect the vision encoder with the LLM. Additionally, LLaVa 1.5 increases the image resolution to 336 x 336 pixels by default, divides the image into patches to facilitate even higher resolutions, and trains on improved data.
Relation to prior work
At the time of publication, vision language models were a relatively new field. Notable vision language models were Flamingo, BLIP-2, Qwen-VL, and Shikra. Researchers first inserted cross attention layers in the LLMs to allow them to attend to visual information. However, this led to more parameters than a simple projection layer. Rather than cross attention, LLaVa uses a simple MLP layer.
Strengths
- LLaVa is extremely data efficient, with a training run only taking a day on 8 A100s (compared to weeks for other modes) for the 13b variant. This drastically reduces the barrier of entry for VLM research and allows researchers to efficiently test their techniques to improve VLMs on a top model.
- LLaVA achieves SOTA on 11 tasks while maintaining a very simple architecture. Unlike other cross attention methods, no layers need to be inserted into the main LLM. The technique can be applied to almost any LLM and vision encoder.
- The paper proposes a simple method of splitting an image into a grid of patches and encoding them separately with CLIP. This is unintuitive but provides better performance than previous methods of adapting CLIP itself for larger resolutions.
Weaknesses
- The paper has limited novel contributions. The differentiating factors between LLaVa 1.5 and LLaVa are the idea of projecting vision embeddings with a MLP instead of a linear layer, a different data mixture, increasing image resolution, and splitting the images into patches. Most of these could be seen as engineering choices rather than novel research ideas.
- Since LLaVa uses CLIP, it must crop images to squares, create out of distribution inputs by resizing the image or pad the image. All of these solutions lose information in the image.
- LlaVa 1.5 was not trained to handle multiple images.
- It would be interesting to see inference-time compute comparisons with the previous cross-attention methods. Cross-attention increases the number of layers but doesn’t increase the number of tokens (width) in other layers of the LLM. On the other hand, projecting tokens to the LLM increases the number of tokens but not the depth of the LLM.
Future Work
There have been many future works that build off of LLaVa. One line of research investigates dynamically splitting up the input image to allow for higher resolutions and varying aspect ratios. Another line of work explores reducing the number of vision embeddings produced from CLIP through numerous methods such as slot attention. This also allows future models to take multiple images as input, something that is not feasible given the 576 vision tokens that a single image produces in LLaVa.
Summary
The paper introduces Unified-IO 2, a generalist model that can process and output numerous modalities. Specifically, Unified-IO 2 can ingest a mixture of text, image, video, audio. It can also output various modalities including images, text, audio, and embodied actions. Notably, Unified-IO 2 achieves SOTA on a generalist benchmark named GRIT. The paper introduces a mixture of demasking tasks to learn the numerous tasks that it targets.
Relation to prior work
There are many prior works on generalist modeling. For example, there is CM3Leon that adapts an LLM to do both VQA and image generation. The most similar work to Unified-IO 2 is Unified-IO. Similar to Unified-IO, Unified-IO 2 uses a transformer encoder-decoder architecture with various additional pretrained, modality-specific encoders and decoders.
Strengths
- Unified-IO 2 doesn’t do task-specific finetuning for any experiments.
- Unified-IO 2 outperforms previous generalist models on most evaluations including GRIT, which consists of many different tasks such as vqa, segmentation, etc.
- Unified-IO 2 achieves competitive performance on VQA tasks as seen in Table 5, even when compared to LLaVa-1.5 13B.
- The paper studies many performance-boosting optimizations such as 2D RoPE, normalizing the queries and keys, scaled cosine attention, and dynamic packing. The paper claims an impressive 4x training throughput with packing.
Weaknesses
- The paper claims that “Unified-IO 2 …. is pre-trained from scratch.” However, it relies on many pretrained encoders and decoders such as ViT, VQ-GAN, AST, and ViT-VQGAN. ViT-VQGAN is the only one that is trained from scratch. One could argue that it would make more sense to simply use these models for the image and audio generation tasks. It is unclear how much Unified-IO 2 contributes to the performance of these models because its performance is never compared to the pretrained models that it uses. For instance, it doesn’t use VQ-GAN as a baseline in the image generation task.
- The paper doesn’t compare image generation quality with previous specialist image generation models in table 4. It only compares TIFA, which measures how well the image follows the prompt.
- None of the top values are bolded in Tables 4, 5, 6, and 7. However, they are bolded in tables 2 and 3.
- Many of the comparisons are with past models that are a lot smaller. For example, Stable Diffusion 1.5 has 860 million parameters
- Unified-IO 2 is beaten by Cube-RCNN on every 3D detection metric in table 7.
Future Work
There are numerous avenues of future work for Unified-IO 2. One such future work is to get rid of the reliance on pretrained modality-specific encoders. For example, they could follow the procedure of the Fuyu model to directly tokenize images into the transformer rather than relying on an encoder.
Summary
The paper introduces C3Net, a method for utilizing diffusion models to condition on and generate different modalities. More concretely, C3Net can generate and condition on text, image, and audio. C3Net trains modality-specific encoders to encode the conditioning into a shared latent space. Then, these latent representations are fed into a control net that shares parameters between modalities. There is also a linear interpolation of the modalities that is fed into the main Unet. After the Unet generates the final latent in the denoising step, the latent is fed into a modality-specific decoder to generate either text, image, or audio.
Relation to prior work
There are many previous works on conditioning diffusion models on multiple modalities and generating multiple modalities. One of the most related works was Composable Diffusion (CoDi), which uses “Bridging Alignment” to align different encoders to the shared latent space. Then, it takes a linear interpolation between these latent embeddings as conditioning for a diffusion model, allowing it to condition on different modalities. Another related work is ControlNet, a method to avoid overfitting when finetuning a diffusion model. ControlNet freezes the Unet in the diffusion model and copies over the parameters to an unfrozen model. Then, the frozen and unfrozen models are connected with “zero-convolutions” in the upsampling stage, which is simply a convolutional layer that is initialized to zeros.
Strengths
- Because of the shared latent space of the encoders, C3Net only needs to make one set of parameters for the ControlNet. Since the ControlNet has the same number of parameters as the original diffusion model, this significantly saves memory when compared to creating separate copies of the model for each modality.
- C3Net improves the linear interpolation method of CoDi with separate ControlNet activations per modality. This theoretically reduces the information lost by averaging the conditioning across modalities in CoDi.
- C3Net seems to align better with the conditioning, as seen in the CLIP scores in tables 2 and 3. Furthermore, metrics indicate that it generates higher quality images, as seen in Inception Score and FID.
Weaknesses
- Although C3Net saves parameters by using the same parameters in the ControlNet across modalities, it still has to compute activations in the entire Unet per modality. Therefore, it may be computationally expensive in terms of flops. Diffusion is already slow during inference because it is highly iterative, and C3Net could further slow down inference.
- C3Net still uses the linear interpolation method as conditioning to the main Unet that was introduced in CoDi. It would be interesting to ablate without this conditioning to see how much the ControlNet contributes and to account for the other minor differences with CoDi.
- The activations from the controller are multiplied by a constant and then connected with the original Unet. This must be empirically evaluated and varies per task.
Future Work
There are many avenues of future work. For instance, researchers could explore learning the multiplication value that connects the ControlNet and Unet. Another line of future work is to incorporate the idea of ControlNet into transformer-based diffusion architectures.
Summary
The paper proposes Language-Regularized Concept Learner (LARC), a method of using natural supervision for 3D visual reasoning and grounding. Compared to previous methods, LARC does not need explicit object-level classification or bounding box labels. Instead, it uses VoteNet for object detections. LARC takes the encoded 3D scene and a query such as “chair above cabinet.” An LLM decomposes the query into a program such as “relate(filter(scene(), chair), filter(scene(), shelf), beside).” Then, the model constructs a n x n matrix for binary relations and n x n x n matrix for ternary relations, taking the argmax corresponding to the query to generate the final answer. LARC also imposes regularization constraints that mimic language properties such as symmetry and exclusivity.
Relation to prior work
The most similar work to LARC is NS3D, which LARC builds upon. NS3D also uses a neuro-symbolic approach for 3D scene understanding but relies on explicit supervised labels. LARC differs from previous 3D scene reference works because it is naturally supervised and imposes language regularization losses.
Strengths
- LARC does not depend on ground truth object classes and bounding boxes. Unlike NS3D, it detects objects directly from scene with VoteNet
- LARC has strong zero shot and transfer abilities (tables 2 & 4), beating out all previous baselines
- LARC is more data efficient than baselines
- Ablations on the he language regularization indicate all of them boost performance.
Weaknesses
- Pair and triplet relations could be expensive to fully compute depending on the number of objects in the image (n^2 and n^3 matrix)
- The following equation was a bit confusing. Why did they not just multiply the relation by the both object classes, for instance sx(y^{chair}) * prob^{beside} * sx(y^{shelf}). Also, the softmax assumes that there is only one of each class in the scene, so the probability sums to 1.
- The paper applies a sparsity loss. It would be nice to see a technique to not fully materialize the n^2 and n^3 matrices (such as thresholding).
- Needs hyperparameters for loss weighing
- The parameter count of LLM could add a large overhead compared to baselines.
- Antonym test set is small (50 examples for table 2)
- The paper doesn’t give the equation for the main L_{pred} loss. The argmin and max in the prediction equation could create sparse gradients.
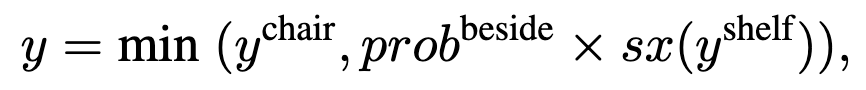
Future Work
There are many avenues of future work. There are VLMs that take in 3D scenes. It would be interesting to adapt these models to use the structured regularization proposed in LARC. Furthermore, they could explore not fully materializing the n^3 and n^2 matrices.
Summary
The paper proposes to use Event Camera as a bridge modality for RGB and LiDAR modalities in scene flow. More specifically, the paper uses a complex fusion process that fuses pairs of modalities–images with event and LiDAR with event. Next, the paper takes these fused modality features along with features from the event camera, adds a KL divergence loss to incentivize them to map to the same space, and performs scene flow with these fused features.
Relation to prior work
There are many previous works on multimodal fusion and scene flow estimation. Many previous works use RGB and LiDAR for scene flow. Another paper, RPEflow, uses RGB, LiDAR, and Event. However, the paper is the first to use their specific fusion method to bridge the intrinsic gap between RGB and LiDAR with event.
Strengths
- The paper proposes the novel idea of using events to bridge RGB and LiDAR modalities and provides strong motivation for why event serves as a good bridge modality.
- Clustering according to the camera characteristics was interesting
- The various fusion methods and alignment losses seem to help according to the table 3 & 4 ablations. The margin of improvement in these ablations is quite large.
- The consistency loss improves performance and smooths gradients, leading to faster convergence (Figure 9)
Weaknesses
- The paper is poorly worded. It would have been nice to include event camera in the related works because I was unfamiliar with this modality, and “event” is a common term.
- Using clustering and K Nearest Neighbors feels inelegant in the LiDAR-event fusion. I wonder if they could do OT or something else to match the event and LiDAR features
- Determining k in the self-similarity clustering requires and lambdas in the loss function require hyperparameter tuning
- The method requires an additional event modality to be captured in conjunction with rgb and LiDAR.
- Figure 8 feels contrived. I wonder how they chose the data points. They also likely used PCA or some other dimensionality reduction. It would be nice to quantitatively evaluate the KL divergence.
- Is it standard to use a non-symmetric function such as KL-divergence to align the modalities? (Equation 11)
- Is the bridge modality lidar in equation 11?
Future Work
There are many avenues of future work. One line of work is to explore applying this fusion method to more modern model architectures. Another possible future work is to replace k nearest neighbors and clustering with a different way to match the LiDAR and event features such as optimal transport. They could also explore (sparse) attention mechanisms to do this. Finally, researchers could compare to simpler fusion methods such as cross attention.
Summary
The paper proposes a planning or “lookahead” method for vision language navigation. More specifically, the proposed model takes in rgb and depth images, converts them to a feature cloud, and samples from this with K-nearest neighbors search when given a candidate location. The candidate locations are predicted by a pretrained waypoint predictor. Given the rgb and depth information of each feature, it is mapped into 3D coordinates which are fed through an encoder. This constructs a tree of possible paths, where the score of each path is predicted with an MLP and is the maximum score of each node along the path.
Relation to prior work
There are many previous works on embodied vision and vision language navigation. Importantly, there are also vision language navigation works that have used neural radiance fields (NeRF) to render the scene in 3D such as GSN, RNR-Map, and Le-RNR-Map. The paper argues that these methods lose fidelity or 3D geometric detail. In contrast, the hierarchical neural radiance network proposed in the paper uses spatial representations, which allegedly leads to better 3D representations.
Strengths
- The paper proposes an elegant way to plan future navigation paths by rendering the locations as neural radiance fields. The tree search with dijkstra's and KD trees to reduce compute requirements was also compelling.
- HNR achieves significant performance gains compared to baselines on R2R-CE and RxR-CE
- The ablations in table 3 indicate that the hierarchical neural radiance network help when compared to previous methods
Weaknesses
- HNR does not perform well on trajectory length (TL in table 1). Also, the paper does not bold the best result for this metric.
- HNR relies on a pretrained waypoint detector.
- Would have liked to see ablation on other losses in table 3 other than L_{region}
- The lookahead procedure seems expensive because of the exponential size of the tree as depth increases. Would like to see compute cost compared to baselines instead of just without certain methods (table 4)
Future Work
There are many possible future works. One weakness of HNR that would be interesting to address is its computational complexity. In future works, researchers can develop heuristics or other prediction methods (using RL for instance) to introduce stop nodes in the tree once there is a certain probability that the branch of the tree will not include the correct path.
Another line of future work is to remove the reliance on depth information. A future model may be able to infer depth from multiple camera angles of the same scene during the navigation process.
Summary
The paper proposes MoReVQA, a training-free method of breaking down VQA tasks into smaller prompts. More specifically, MoReVQA uses an event parsing phase, grounding phase, and reasoning phase. The phases update a shared memory to provide context between phases. The parsing phase converts the video into events with an LLM that outputs API calls. The grounding phase also uses an LLM to output API calls that access instructions that may access the video. Finally, the reasoning phase uses an LLM to produce API calls given the external memory that also can access the video and update the memory. After the 3 phases, the video context and external memory are fed into a prediction LLM along with the question to produce the final answer.
Relation to prior work
There are many previous training-free methods to improve VQA performance and interpretability. One such method is ViperGPT, which outputs a program (in Python for instance) to process a video. Unlike end-to-end methods, the code that ViperGPT produces is interpretable. The paper argues that MoReVQA has several advantages over ViperGPT such as decomposing the task into multiple stages and mitigating the sensitivity of the planning phase.
Strengths
- MoReVQA is training free
- MoReVQA is interpretable. For example, you can see qualitative interpretable results in Figure 4.
- MoReVQA outperforms baselines on VQA (table 1)
- The ablations indicate that all 3 stages improve results in the final VQA benchmarks.
Weaknesses
- MoReVQA is not very novel. It is basically a prompt engineering method.
- Inference may be expensive because it is highly sequential and prompts the LLM multiple times. It is also unclear how fast the API calls are and whether each call is a parallelizable/efficient operation.
- All of the stages use an LLM instead of VLM. In the grounding stage, although the LLM may query the video, it doesn’t have direct access to the video to generate these queries. Similarly, the event parsing stage may lose information when compared to directly projecting the video into an LLM such as in LLaVA.
- The external memory and video context that is fed into the prediction LLM seems to be highly structured. Therefore, the diversity of responses from MoReVQA may be limited when compared to end-to-end methods such as mplug-owl3 or intern-vl.
- The paper did not compare against general VLMs (ex: llava-next-neterleve). On the one dataset that I looked up, MoReVQA did not beat existing end-to-end methods.
Future Work
Chain-of-thought is another method of gaining insight into the inner workings of an LLM. It would be interesting to teach a VQA model to use RL and chain-of-thought to dynamically output API calls when needed.
Summary
The paper proposes VQA-GNN, a method for visual question answering with graph neural networks. More specifically, the paper introduces super nodes to bidirectionally connect a scene graph and concept graph unlike past methods that use unidirectional connections. VQA-GNN introduces a supernode Z, which serves to connect the separately extracted scene and concept graphs. Concretely, Z connects the graphs with question, answer, and image edges, each of which points to their respective concept nodes. After connecting both graphs, the authors use a pretrained language model encoder to encode the Z node, along with separate graph neural networks (one on the scene graph and one on the concept graph) to reason across the graphs and query.
Relation to prior work
There are many prior works for visual question answering (VQA). The first line of work uses multimodal transformers and structured graphs such as RESERVE-L. The paper argues that these works don’t utilize structured knowledge. Another line of work uses more structured knowledge and scene graphs to perform VQA. Unlike previous methods, VQA-GNN allows for bidirectional fusion and therefore interaction between the scene and knowledge graphs.
Strengths
- The paper proposes the novel Z super node idea to connect the scene and concept graphs. Ablations indicate that this node is important for downstream performance
- VQA-GNN beats UNITER-L, which requires 32x pretraining data
- VQA-GNN achieves SOTA
- Most design choices seem to help performance. Table 2 ablations indicate that the concept graph, scene graph, and node p help. Table 3 ablations indicate that separate GNNs help.
- The bidirectional motivation is compelling. It makes sense that the z node should allow interactions between the scene and knowledge graphs. Furthermore, ablations indicate that bidirectional fusion is beneficial.
Weaknesses
- The scene graph extractor could lose detail from the image. When compared to MLLM methods that directly embed the image into the LLM, using 20 nodes to represent an image seems like it could lose some information. It would make more sense to limit the number of nodes on the text side.
- The performance boost on VCR is small when compared to UNITER-L. The only difference is in Q -> A by 0.6%. The performance boost claimed throughout the paper is from combining VQA-GNN with RESERVE-L, which uses 1 billion parameters.
- Only objects in ConceptNetKG are grounded. It would not generalize to unseen objects.
- The method filters relevance scores < 0.6. This could be a very manual hyperparameter to set.
Future Work
There are many lines of possible future work. One line would be to use a pretrained LLM rather than a GNN to allow for more open-domain VQA.
Summary
The paper proposes Debiasing with Additive Residuals (DEAR), a method to debias vision language models such as CLIP. Specifically, DEAR trains a lightweight model to add a vector to the visual CLIP embedding. This added residual aims to decrease the accuracy of an adversarial classifier that outputs protected attributes such as gender, race, and age. The paper also does preliminary experiments to show that there exists an image encoding that matches the text encoding of protected attributes such as race, which theoretically supports their residual method. The paper also introduces the protected attribute tag association dataset, which includes biases of race, age, and gender.
Relation to prior work
There are many related works in the space of VLMs and bias correction. There have been many debiasing works for unimodal models such as text, vision, and graphs. However, the authors of dear point out that debiasing in the multimodal space poses unique challenges such as data requirements and compute restraints. Previous works on debiasing VLMs have removed dimensions in CLIP and used adversarial finetuning. However, the authors claim that these methods are limited in handling multiple protected attributes and maintaining model performance.
Strengths
- DEAR reduces the ability for various models such as CLIP to discriminate between protected attributes, as shown in tables 1 and 2
- DEAR can use a pretrained adversarial classifier, leading to more stable training
- The Additive Residual Learner is lightweight
Weaknesses
- DEAR decreases the performance of models across the board according to Table 3.
- The method feels very simple. Previous methods have used an adversarial classifier. The addition of learning a residual may not be very novel, especially when previous works have explored vector arithmetic in the embedding space (like queen + man - woman = king)
- The motivation to only apply this to image encoder was weak. The authors claim that learning a residual in the visual stream is better “because the encoding from it captures rich information in a compact form” However, both modalities encode to the same compact embedding shape. I don’t see why they can’t perform the same technique on text.
- In equation 8, A and K are not guaranteed to be invertible
Future Work
There are many avenues of future work. One such line of work is to jointly train the VLMs on their original tasks and the debiasing tasks to attempt to maintain their zero-shot performance. Another line of work is to apply DEAR on the text stream. Researchers could also extend the debiasing methods to more attributes other than gender, race, and age. For instance, they could investigate detecting religion or political affiliation. Finally, future works could investigate training free methods of debiasing. For instance, they could experiment with adding or subtracting the embeddings of certain genders during the similarity calculation.
Discussion Questions for Guest Lecturer Yake Wei (Primary Paper: Enhancing Multimodal Cooperation via Sample-level Modality Valuation, Secondary Paper: Balanced Multimodal Learning via On-the-fly Gradient Modulation)
Weaknesses
- The method scales with the number of permutations of modalities. Therefore it scales with n! where n is the number of modalities. This could be very expensive especially with generalist models such as uniperciever.
- The paper says that “FLOPs of our methods reduce ¼ (sample-level method), even ½ (modality-level method), compared to G-Blending.” However, although they numerically evaluated FLOPs, there is no table comparing FLOPs to baselines.
- The frequencies are updated once per epoch. However, modality importance could change over the course of training. Specifically, modality importance could drift from the sampled frequencies later on in an epoch.
Questions
Primary Paper
- Why are permutations instead of combinations used to calculate phi (equations 2 and 3)? The input modalities to a model aren’t ordered. Won’t some modality sets be double counted? For instance, {1, 2, 3} and {2, 1, 3} will contribute the same delta value. Furthermore, if my understanding is correct, equation 3 will weigh combinations with less modalities more because when x^i appears earlier in the permutation, it will be double counted more. For instance, if n = 6 and x^i appears 2nd in the permutation, there are 6 unique S_{pi}(x^i), but if x^i appears second, there are 6 * 5 unique S{pi}(x^i). It would make sense to assign higher weight to inputs with more modalities. Using combinations would also save compute.
- Sample-level and Modality-level do similarly on MM-Debiased. However, the dataset-level (modality-level) discrepancy is not supposed to be significant in MM-Debiased. Therefore, why is there not a larger difference between sample and modality level on this dataset?
- Have you considered evaluating the uni-modal contribution more than once per epoch or setting a dynamic schedule for this?
Secondary Paper
- Do methods other than concatenation suffer from the same optimization issues discussed in section 3.1? For instance, many modern diffusion models use multimodal transformers (mmdit). Similarly, in LLaVA, the different modalities are fed jointly through self attention rather than simple vector concatenation. How does pure OGM perform on fusion methods other than concatenation?
- How much does adding additional noise to the gradient without applying OGM affect performance? In other words, how much of the performance increase is due to the stochasticity? It looks like momentum optimizers such as Adam benefit less from this method, possibly because they smooth out the additional noise.
- Did they consider normalizing the softmax in equation 8 by the dimension of the logits?
- Can you apply OGM-GE to more than 2 modalities?